choosistant
Helps you decide which product to buy by summarizing pros and cons from written product reviews.
What is it?
Choosistant is an ML-powered system which helps you decide which product to buy by summarizing the pros and cons from written product reviews. The system leverages an NLP model to predict spans of text describing product features which are considered to be good and bad by reviewers.

Who made it?
- Kimotho LinkedIn GitHub
- Murad Khalilov LinkedIn GitHub
- Nam LinkedIn GitHub
- Omar Ali Sheikh LinkedIn GitHub
- Sofiane LinkedIn
Why is it useful?
We all experience it. You need to buy a new weighing scale. Your old scale stopped working. You want to replace it in a hurry. A quick search on amazon.com and you find a weighing scale with the Amazon’s Choice tag:
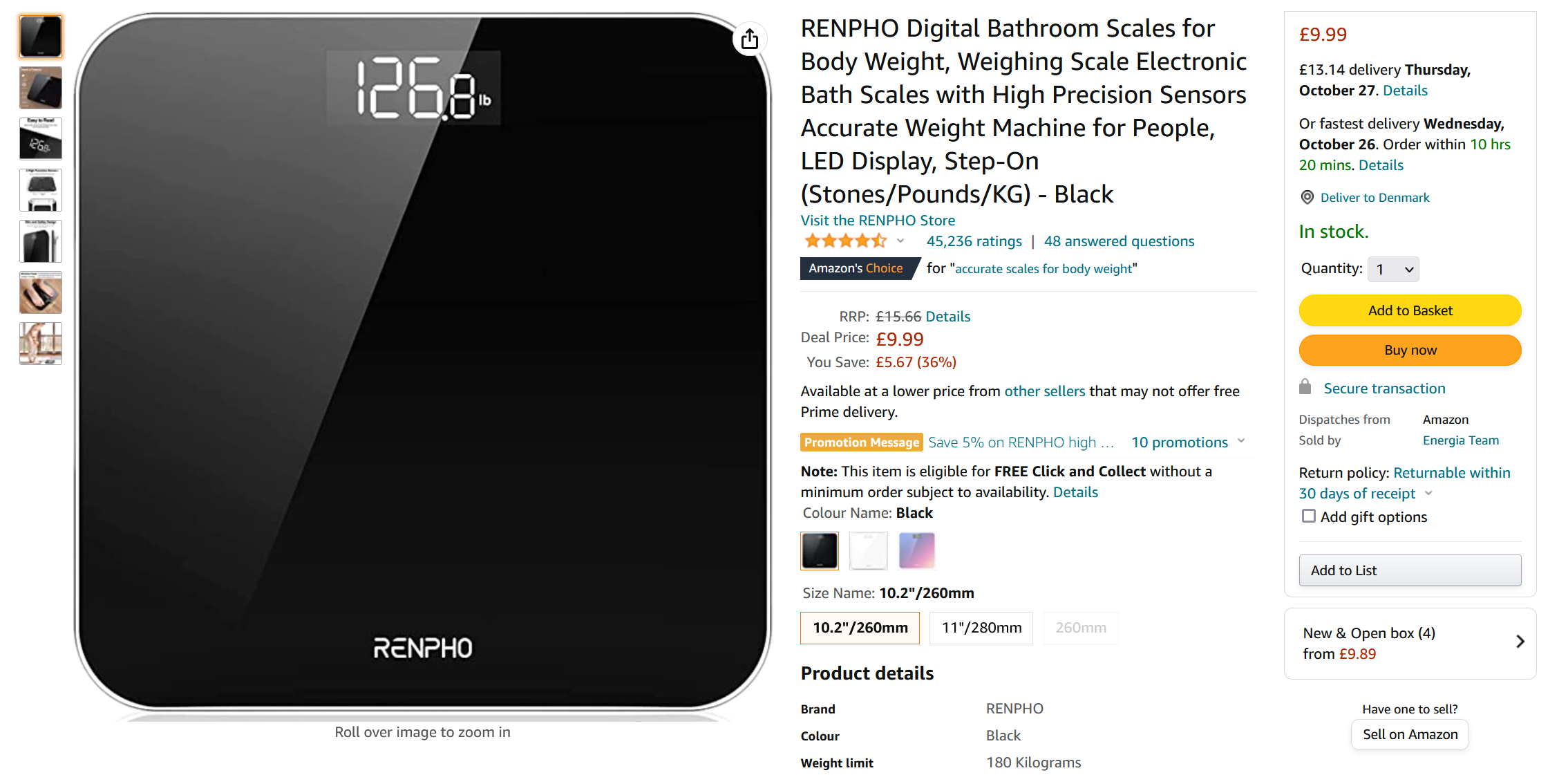
The product looks slick, is highly rated and reasonably priced. But before clicking on the screaming Buy Now button, you are curious about what other people are saying about this product. Mostly the reviews are positive and say good things about the scale. But then you stumble on a seemingly positive review:

Wait, what?! So this weighing scale cannot even provide its basic functionality correctly? You find other consumers reporting similar inaccuracies:

It seems that this scale is neither consistent nor accurate with its measurements. You also find worrying reviews about the scale’s robustness.
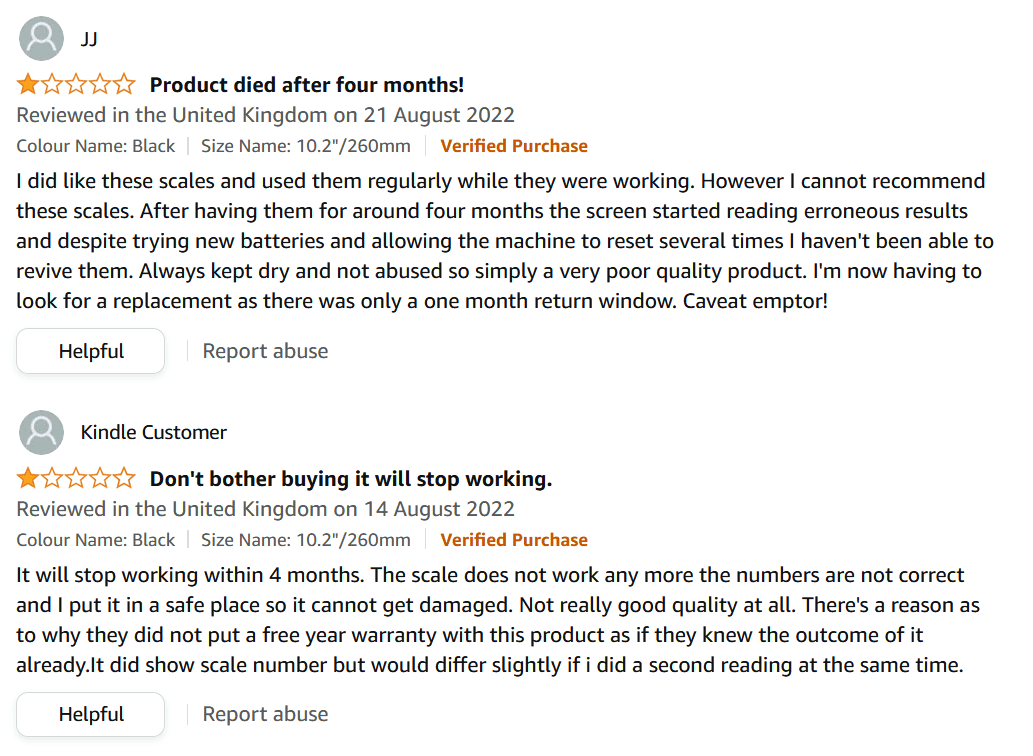
Now what? You look for alternative products and read their reviews. Soon, you are spending a huge amount of time reading a bunch of reviews, wishing there was a way to have a summary of all the reviews in one place. Enter choosistant!
How did we approach the problem?
The problem is as follows:
- We have a bunch of written customer reviews about a given product.
- We want to extract specific phrases in the original text.
- The extracted text must highlight product features which are considered good or bad by other consumers.
There are several ways to frame this problem as a machine learning task. One approach is to perform traditional sentiment analysis and capture words that get high attention. However, it is not clear how to aggregate these results into coherent pros and cons. Another approach is to formulate the problem as a summarization task. The main issue is that summarization models tend to hallucinate i.e. include phrases and words that are not part of the original text. We found that the best method is to cast the problem as an Extractive Question Answering (QA) task. This alleviates the hallucination issue with text summarizers.
If you want to more about how Extractive QA works, please read the excellent articles written by the folks at Hugging Face and deepset.
System overview
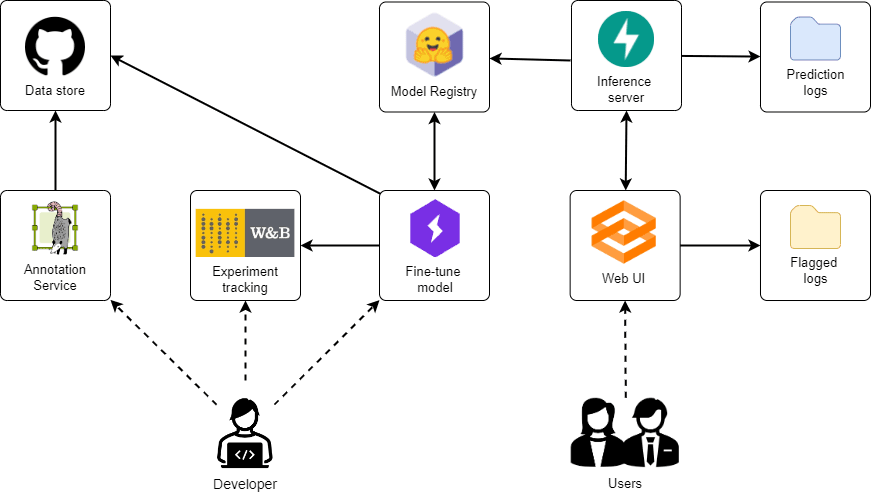
Data
Although the pre-trained QA model by deepset seemed promising, its predictions were qualitatively not great. We needed a way to fine-tune the pre-trained model to our task at hand. For this, we had to annotate a training set. First, we wrote an annotation guideline because we wanted to ensure consistent annotations. Early on, we identified that one big risk for the project was annotations being inconsistent and thus creating bad models. Then we sampled a small set (~200 reviews) from the Amazon Review data set and began the annotation process using Label Studio.
We wanted to get an MVP up and running quickly so we could iterate on it. Since our sampled data was not very large, we created a GitHub repo to store Label Studio’s artifacts including SQLite database, reviews in JSON files and exported annotations in JSON.
Reflections
- Some of the reviews were difficult to annotate. We learned that there was a need to provide more contextual information (e.g. name, brief description, pictures etc. of the product) in the annotation interface. This context should help annotators be better at disambiguating phrases in the review text.
- Despite our best efforts, there are still inconsistent annotations in the training set. Standard practice for overcoming this challenge is to collect more than one annotation for the same piece of text. Then find a way to handle disagreements between the annotators. In addition, it allows us to measure the extent to which the output of the annotation process can be repeated and scaled.
- Ensuring the quality of the annotations is important. However, we did not put a proper quality assurance step in place to check what the training set looked like. We did manual spot checks. However, that does not scale and is to repeatable. To create a data flywheel, we need a QA process.
- Instead of using GitHub as our storage repo, an alternative option might be to upload the data to Hugging Face Dataset as a fellow FSDL student did.
Models
The annotated data were used to fine-tune both the QA model as well as a seq2seq model. We created an account for Weights & Biases, and incorporated it in the trainer. Pytorch Lightning make things easy. However, we did not fully utilize W&B because we did not perform a lot of experiments with our models. Once a model was fine-tuned, we stored the model artefacts on Hugging Face Models, essentially using the HF service as a light-weight model registry.
Reflections
- Use a true model registry that allows us to not only track model versions but also information surrounding the fine-tuning process. This includes information like what code was used to fine-tune the model (Git SHA), what are the characteristics of the training data (data profile), and the results of the experiments that produced the model (link to experiment tracking service).
Inference service
Our models were downloaded by the inference server and used to make predictions. We used FastAPI to expose a /predict REST-endpoint. The app assigns each request a unique ID and logs information about the request, the output of the model, inference time and device (CPU or GPU). The prediction ID is sent as part of the HTTP response such that any logging that happens on the client side can be linked to the predictions made by inference service.
Reflections
- The inference speed on GPU is around 800 ms while it is 10 times slower on the CPU. To speed things up, we are considering experimeting Hugging Face Optimum.
User Interface
In order to interact with our models, we built a simple user interface using Gradio. We were able to quickly put together a skeleton UI that interacts with the inference service and presents the results to the user. The user can flag the output of the model.
Reflections
- Our experience developing a UI on Gradio was a bit painful. It was easy to write a simple UI, but customizing and debugging the Gradio app was frustrating. Briefly, we considered port the UI code to Streamlit. We skipped this idea because our aim was to create a browser extension that summarizes pros and cons in-site.